
O quão popular é o seu nome?
No Censo 2010, o IBGE incorporou no levantamento a coleta de nomes (apenas o primeiro) e sobrenome (apenas o último). Para quem é curioso por coisas sem muita utilidade prática (e eu jogo forte nesse time!), vale a pena entrar no site https://censo2010.ibge.gov.br/nomes e conferir as estatísticas do nome de interesse.
O site é legal, mas eu queria ter os dados na mão para fazer as coisas do meu jeito. Então decidi escrever um pacote no R para acessar os dados da API que o IBGE montou para esse banco.
O pacote chama brnome e está disponível no meu Github.
if (!require("pacman")) install.packages("pacman")
pacman::p_load(readr, dplyr, purrr, tidyr, ggplot2, forcats, wordcloud)
pacman::p_load_gh("italocegatta/brnome")
pacman::p_load_gh("italocegatta/brmap")Vamos começar com a função brnome_freq() e entender a distribuição espacial e temporal (década de nascimento) do nome da minha queria e sapeca sobrinha, Eliza.
eliza_freq <- brnome_freq(nome = "eliza")
eliza_freq## # A tibble: 9 x 7
## nome sexo localidade_cod localidade_nome nascimento_peri~
## <chr> <lgl> <chr> <chr> <chr>
## 1 ELIZA NA BR Brasil [ , 1930]
## 2 ELIZA NA BR Brasil [1930, 1940]
## 3 ELIZA NA BR Brasil [1940, 1950]
## 4 ELIZA NA BR Brasil [1950, 1960]
## 5 ELIZA NA BR Brasil [1960, 1970]
## 6 ELIZA NA BR Brasil [1970, 1980]
## 7 ELIZA NA BR Brasil [1980, 1990]
## 8 ELIZA NA BR Brasil [1990, 2000]
## 9 ELIZA NA BR Brasil [2000, 2010]
## # ... with 2 more variables: nascimento_decada <int>, frequencia <int>Notem que as colunas sexo e localidade estão vazias pois não foram especificadas. Significa que foi considerada a busca de homens e mulheres para todo o Brasil.
Será que tem algum homem batizado com o nome Eliza? Tem, e eu não sei se foi de propósito ou se foi um erro de coleta. Fica aí o questionamento hehehehe.
brnome_freq(nome = "eliza", sexo = "m")## # A tibble: 9 x 7
## nome sexo localidade_cod localidade_nome nascimento_peri~
## <chr> <chr> <chr> <chr> <chr>
## 1 ELIZA M BR Brasil [ , 1930]
## 2 ELIZA M BR Brasil [1930, 1940]
## 3 ELIZA M BR Brasil [1940, 1950]
## 4 ELIZA M BR Brasil [1950, 1960]
## 5 ELIZA M BR Brasil [1960, 1970]
## 6 ELIZA M BR Brasil [1970, 1980]
## 7 ELIZA M BR Brasil [1980, 1990]
## 8 ELIZA M BR Brasil [1990, 2000]
## 9 ELIZA M BR Brasil [2000, 2010]
## # ... with 2 more variables: nascimento_decada <int>, frequencia <int>A pesquisa também pode ser feita para um determinado município ou estado. Neste caso, você precisa utilizar o código oficial do IBGE de localidades. Como exemplo, vamos ver os resultados para Cuiabá (5103403) e Mato Grosso (51).
brnome_freq(nome = "eliza", localidade_cod = 5103403)## # A tibble: 7 x 7
## nome sexo localidade_cod localidade_nome nascimento_peri~
## <chr> <lgl> <int> <chr> <chr>
## 1 ELIZA NA 5103403 Cuiabá [1940, 1950]
## 2 ELIZA NA 5103403 Cuiabá [1950, 1960]
## 3 ELIZA NA 5103403 Cuiabá [1960, 1970]
## 4 ELIZA NA 5103403 Cuiabá [1970, 1980]
## 5 ELIZA NA 5103403 Cuiabá [1980, 1990]
## 6 ELIZA NA 5103403 Cuiabá [1990, 2000]
## 7 ELIZA NA 5103403 Cuiabá [2000, 2010]
## # ... with 2 more variables: nascimento_decada <int>, frequencia <int>brnome_freq(nome = "eliza", localidade_cod = 51)## # A tibble: 9 x 7
## nome sexo localidade_cod localidade_nome nascimento_peri~
## <chr> <lgl> <int> <chr> <chr>
## 1 ELIZA NA 51 Mato Grosso [ , 1930]
## 2 ELIZA NA 51 Mato Grosso [1930, 1940]
## 3 ELIZA NA 51 Mato Grosso [1940, 1950]
## 4 ELIZA NA 51 Mato Grosso [1950, 1960]
## 5 ELIZA NA 51 Mato Grosso [1960, 1970]
## 6 ELIZA NA 51 Mato Grosso [1970, 1980]
## 7 ELIZA NA 51 Mato Grosso [1980, 1990]
## 8 ELIZA NA 51 Mato Grosso [1990, 2000]
## 9 ELIZA NA 51 Mato Grosso [2000, 2010]
## # ... with 2 more variables: nascimento_decada <int>, frequencia <int>Para consultar os códigos das localidades, o pacote disponibiliza um dataframe auxiliar localidades.
localidades## # A tibble: 5,597 x 3
## localidade localidade_nome tipo
## <chr> <chr> <chr>
## 1 1100015 Alta Floresta D'Oeste Município
## 2 1100023 Ariquemes Município
## 3 1100031 Cabixi Município
## 4 1100049 Cacoal Município
## 5 1100056 Cerejeiras Município
## 6 1100064 Colorado do Oeste Município
## 7 1100072 Corumbiara Município
## 8 1100080 Costa Marques Município
## 9 1100098 Espigão D'Oeste Município
## 10 1100106 Guajará-Mirim Município
## # ... with 5,587 more rowsBom, consultas simples como está podem ser feitas diretamente pelo site do IBGE, mas podemos deixar um pouco mais complexo e pegar a frequência do nome Eliza para todos os estados do Brasil.
eliza_estado <- localidades %>%
filter(tipo == "Estado") %>%
mutate(
freq = map(
localidade,
~brnome_freq(nome = "Eliza", localidade_cod = .x)
)
) %>%
select(freq) %>%
unnest()
eliza_estado## # A tibble: 218 x 7
## nome sexo localidade_cod localidade_nome nascimento_peri~
## <chr> <lgl> <int> <chr> <chr>
## 1 ELIZA NA 11 Rondônia [1940, 1950]
## 2 ELIZA NA 11 Rondônia [1950, 1960]
## 3 ELIZA NA 11 Rondônia [1960, 1970]
## 4 ELIZA NA 11 Rondônia [1970, 1980]
## 5 ELIZA NA 11 Rondônia [1980, 1990]
## 6 ELIZA NA 11 Rondônia [1990, 2000]
## 7 ELIZA NA 11 Rondônia [2000, 2010]
## 8 ELIZA NA 12 Acre [1940, 1950]
## 9 ELIZA NA 12 Acre [1960, 1970]
## 10 ELIZA NA 12 Acre [1970, 1980]
## # ... with 208 more rows, and 2 more variables: nascimento_decada <int>,
## # frequencia <int>Primeiro vamos analisar a frequência do nome pela década de nascimento somando os valores de todos os estados.
eliza_estado %>%
group_by(nascimento_decada) %>%
summarise(frequencia = sum(frequencia)) %>%
ggplot(aes(nascimento_decada, frequencia)) +
geom_line(size = 1) +
geom_point(shape = 21, color = "white", fill = "#80b1d3", size = 7, stroke = 2) +
labs(x = "Década de nascimento", y = "Frequência do nome Eliza") +
scale_x_continuous(breaks = seq(1900, 2020, 10)) +
scale_y_continuous(limits = c(0, NA), labels = scales::unit_format(unit = "k", scale = 1e-3)) +
theme_bw(16)
Também podemos ver a distribuição espacial pelos estados do Brasil.
eliza_estado %>%
left_join(brmap_estado_simples, by = c("localidade_nome" = "estado_nome")) %>%
st_as_sf() %>%
ggplot(aes(fill = frequencia)) +
geom_sf(color = "white") +
scale_fill_distiller(palette = "Purples", direction = 1) +
labs(fill = "Frequência do nome Eliza") +
theme_bw(16) +
theme(legend.position = "bottom", legend.justification = "right") +
guides(fill = guide_colorbar(barwidth = 15, title.position = "top"))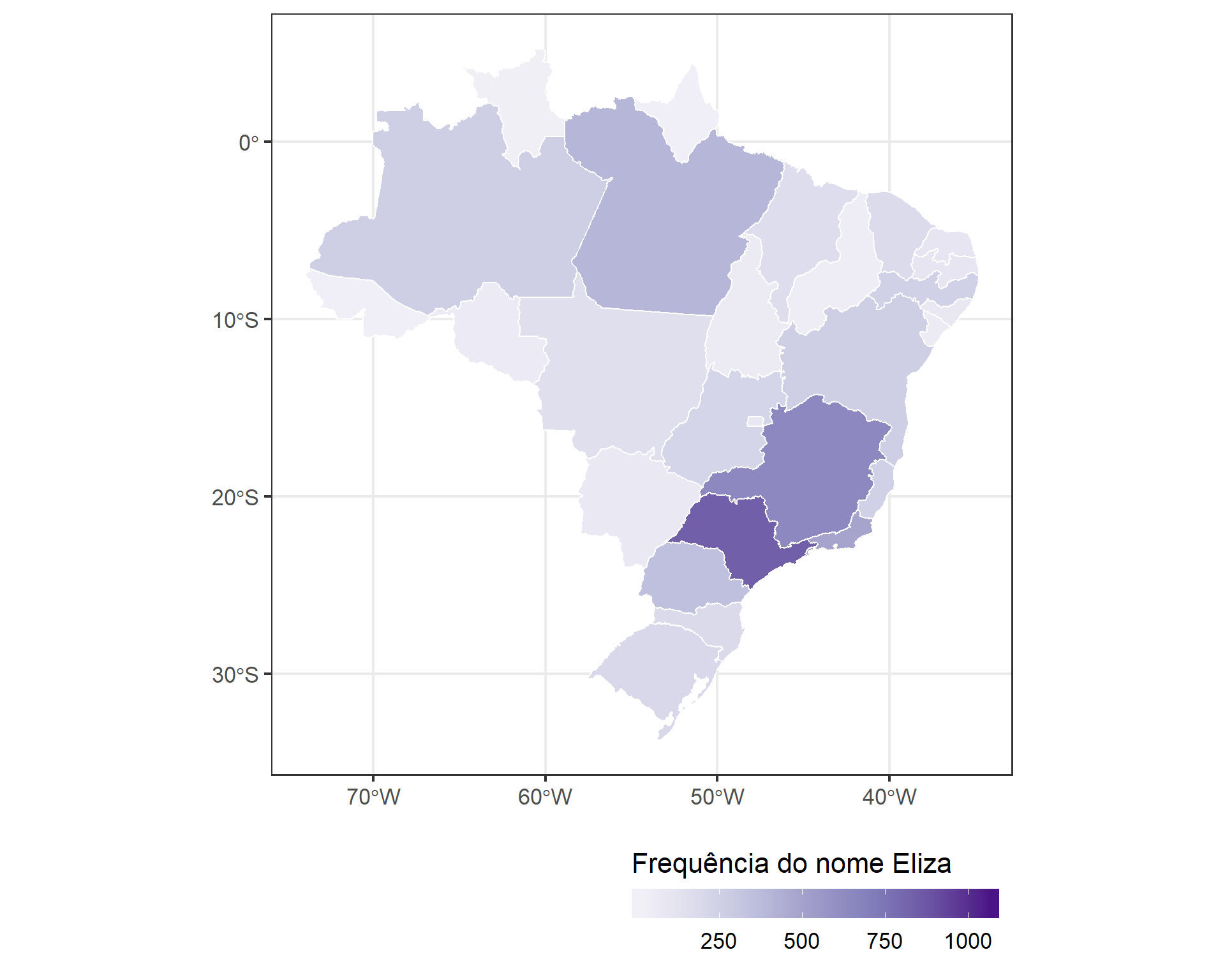
A segunda função presente no pacote acessa o rank dos nomes mais populares por sexo, década de nascimento e localidade.
rank_decada <- map_dfr(seq(1930, 2000, 10), ~brnome_rank(decada = .x))
rank_decada %>%
ggplot(aes(decada, ranking, fill = frequencia, label = nome)) +
geom_line(aes(group = nome), alpha = 0.5) +
geom_label(color = "black", size = 3) +
#facet_wrap(~sexo, labeller = labeller(sexo = c("F" = "Feminino", "M" = "Masculino"))) +
labs(x = "Décade de nascimento", y = "Ranking", fill = "Frequência") +
scale_x_continuous(breaks = seq(1930, 2000, 10)) +
scale_y_reverse(breaks = 1:20) +
scale_fill_distiller(
palette = "PuBuGn", direction = 1,
labels = scales::unit_format(unit = "k", scale = 1e-3)
) +
theme_bw() +
theme(legend.position = "bottom", legend.justification = "right") +
guides(fill = guide_colorbar(barwidth = 20, title.position = "top"))
Para finalizar, vamos fazer um gráfico com os nomes mais frequentes em forma de nuvem de palavras.
top_nomes <- bind_rows(
brnome_rank(sexo = "f"),
brnome_rank(sexo = "m")
)
set.seed(1)
wordcloud(top_nomes$nome, top_nomes$frequencia, scale=c(8, 1))
Caso tenha alguma dúvida ou sugestão sobre o post, fique à vontade para fazer um comentário ou me contatar por E-mail.
sessioninfo::session_info(c("readr", "dplyr", "purrr", "tidyr", "ggplot2", "forcats", "brmap", "brnome", "wordcloud"))## - Session info ----------------------------------------------------------
## setting value
## version R version 3.5.3 (2019-03-11)
## os Windows 10 x64
## system x86_64, mingw32
## ui RTerm
## language (EN)
## collate Portuguese_Brazil.1252
## ctype Portuguese_Brazil.1252
## tz America/Sao_Paulo
## date 2019-08-25
##
## - Packages --------------------------------------------------------------
## package * version date lib
## askpass 1.1 2019-01-13 [1]
## assertthat 0.2.1 2019-03-21 [1]
## backports 1.1.4 2019-04-10 [1]
## BH 1.69.0-1 2019-01-07 [1]
## brmap * 0.1.0 2019-03-04 [1]
## brnome * 0.0.0.9000 2019-07-08 [1]
## class 7.3-15 2019-01-01 [2]
## classInt 0.4-1 2019-08-06 [1]
## cli 1.1.0 2019-03-19 [1]
## clipr 0.7.0 2019-07-23 [1]
## colorspace 1.4-1 2019-03-18 [1]
## crayon 1.3.4 2017-09-16 [1]
## curl 4.0 2019-07-22 [1]
## DBI 1.0.0 2018-05-02 [1]
## digest 0.6.20 2019-07-04 [1]
## dplyr * 0.8.3 2019-07-04 [1]
## e1071 1.7-2 2019-06-05 [1]
## ellipsis 0.2.0.1 2019-07-02 [1]
## fansi 0.4.0 2018-10-05 [1]
## forcats * 0.4.0 2019-02-17 [1]
## ggplot2 * 3.2.1 2019-08-10 [1]
## glue 1.3.1 2019-03-12 [1]
## gtable 0.3.0 2019-03-25 [1]
## hms 0.5.0 2019-07-09 [1]
## httr 1.4.1 2019-08-05 [1]
## jsonlite 1.6 2018-12-07 [1]
## KernSmooth 2.23-15 2015-06-29 [2]
## labeling 0.3 2014-08-23 [1]
## lattice 0.20-38 2018-11-04 [2]
## lazyeval 0.2.2 2019-03-15 [1]
## magrittr 1.5 2014-11-22 [1]
## MASS 7.3-51.1 2018-11-01 [2]
## Matrix 1.2-17 2019-03-22 [1]
## mgcv 1.8-28 2019-03-21 [1]
## mime 0.7 2019-06-11 [1]
## munsell 0.5.0 2018-06-12 [1]
## nlme 3.1-137 2018-04-07 [2]
## openssl 1.4.1 2019-07-18 [1]
## pillar 1.4.2 2019-06-29 [1]
## pkgconfig 2.0.2 2018-08-16 [1]
## plogr 0.2.0 2018-03-25 [1]
## plyr 1.8.4 2016-06-08 [1]
## purrr * 0.3.2 2019-03-15 [1]
## R6 2.4.0 2019-02-14 [1]
## RColorBrewer * 1.1-2 2014-12-07 [1]
## Rcpp 1.0.2 2019-07-25 [1]
## readr * 1.3.1 2018-12-21 [1]
## reshape2 1.4.3 2017-12-11 [1]
## rlang 0.4.0 2019-06-25 [1]
## rvest 0.3.4 2019-05-15 [1]
## scales 1.0.0 2018-08-09 [1]
## selectr 0.4-1 2018-04-06 [1]
## sf * 0.7-7 2019-07-24 [1]
## stringi 1.4.3 2019-03-12 [1]
## stringr 1.4.0 2019-02-10 [1]
## sys 3.2 2019-04-23 [1]
## tibble 2.1.3 2019-06-06 [1]
## tidyr * 0.8.3 2019-03-01 [1]
## tidyselect 0.2.5 2018-10-11 [1]
## units 0.6-3 2019-05-03 [1]
## utf8 1.1.4 2018-05-24 [1]
## vctrs 0.2.0 2019-07-05 [1]
## viridisLite 0.3.0 2018-02-01 [1]
## withr 2.1.2 2018-03-15 [1]
## wordcloud * 2.6 2018-08-24 [1]
## xml2 1.2.2 2019-08-09 [1]
## zeallot 0.1.0 2018-01-28 [1]
## source
## CRAN (R 3.5.2)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
## local
## Github (italocegatta/brnome@85a10a7)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.2)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
## CRAN (R 3.5.3)
## CRAN (R 3.5.0)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.1)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
## CRAN (R 3.5.0)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.3)
## CRAN (R 3.5.1)
## CRAN (R 3.5.1)
## CRAN (R 3.5.2)
## CRAN (R 3.5.3)
## CRAN (R 3.5.2)
##
## [1] C:/Users/Italo/Documents/R/win-library/3.5
## [2] C:/Program Files/R/R-3.5.3/library